-
네이버 쇼핑 내 등록된 홍삼/종합비타민/유산균 제품 브랜드 알아보자Data Analysis/Investment 2021. 4. 8. 13:13
네이버에서는 특정 키워드를 검색했을 때 나오는 쇼핑 결과를 API로 제공해주고 있다. 그래서 이번 포스팅에서는 요즘 엄청나게 성장 중인 홍삼, 비타민, 유산균 등의 건강기능식품의 주요 플레이어 브랜드가 어디 있는지 알아보도록 하겠다.
1. 홍삼 브랜드
홍삼 같은 경우 분석 안 해도 어느 정도 예측이 가능하다. 왜냐하면 국내 홍삼 시장은 정관장이 거의 점유하고 있기 때문이다. 아래 그래프에서 볼 수 있듯이 네이버에 정관장 홍삼 제품이 356개가 등록되어 있다. 그 외 나머지 브랜드를 다 합쳐도 정관장 하나에도 못 미친다. 홍삼 시장에서는 딱히 얘기할 내용이 없어 보인다.
*API에서 가져올 수 있는 데이터의 제한이 있기 때문에 아래 데이터가 100% 정확하지는 않다.
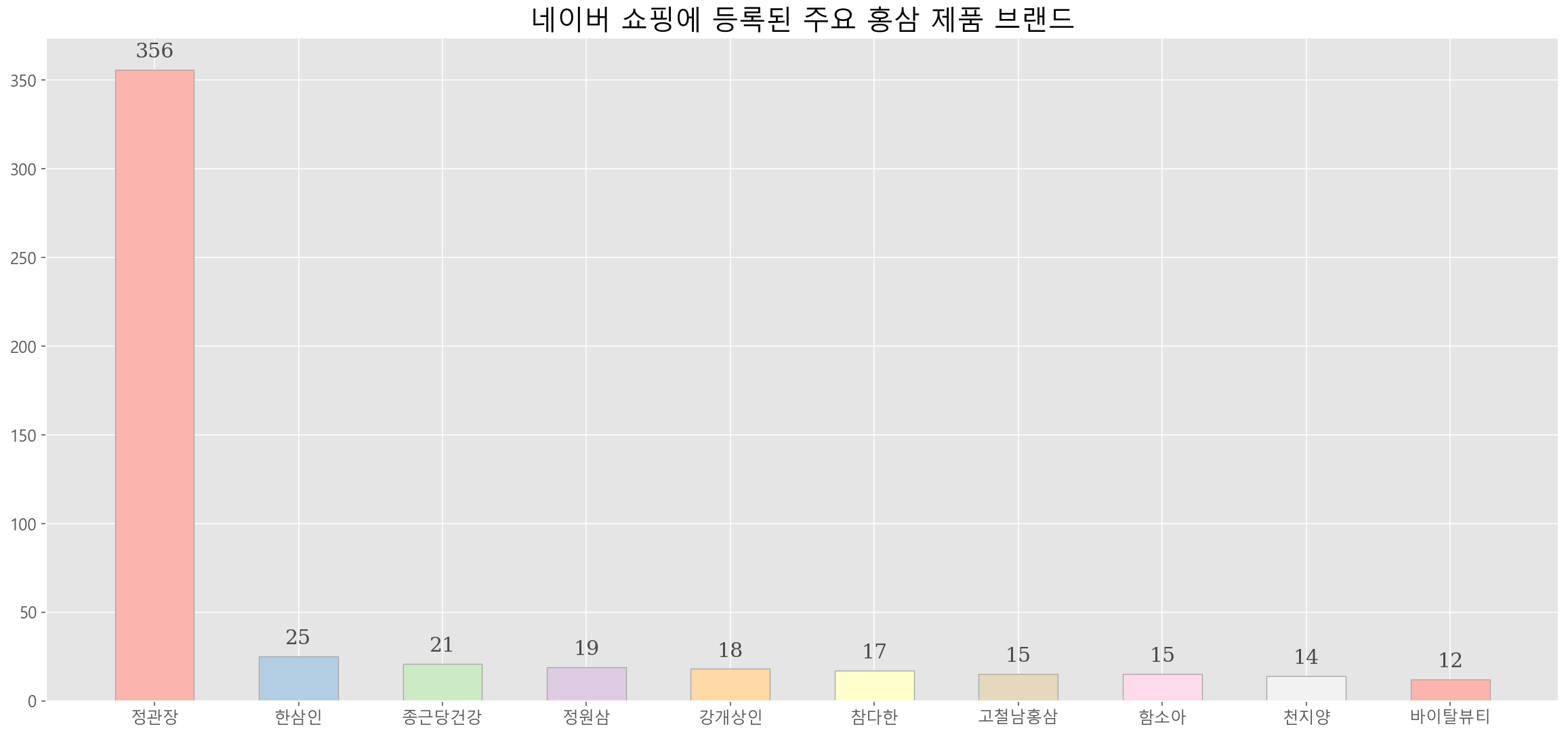
import urllib.request import requests import pandas as pd header_parms ={"X-Naver-Client-Id":'~~',"X-Naver-Client-Secret":'~~'} keywords='홍삼' data=[] for i in range(1,1001): api = f"https://openapi.naver.com/v1/search/shop.json?query={keywords}&display=100&start={i}" # json 결과 res=requests.get(api,headers=header_parms) if res.json(): for a in res.json()['items']: if a not in data: data.append(a) else: continue df=pd.DataFrame(data) df=df.drop_duplicates(['link'],keep='first') df2=df[df['category3']=='홍삼'] brand=pd.DataFrame(df2.groupby(['brand']).count()['title']).reset_index() brand_=brand.sort_values(by='title',ascending=False) brand_=brand_[brand_['brand']!=''] brand_.columns=['Brand','Number of Products'] brand_top_10=brand_.head(10) import seaborn as sns import matplotlib.pyplot as plt from IPython.display import set_matplotlib_formats set_matplotlib_formats("retina") plt.style.use('ggplot') plt.rcParams["font.size"] = 12 plt.rcParams["font.family"] = 'Malgun Gothic' fig, ax = plt.subplots(1,1, figsize=(20, 9)) ax.bar(brand_top_10.Brand, brand_top_10['Number of Products'], width=0.55, edgecolor='darkgray', color=sns.color_palette("Pastel1"), linewidth=0.7) ax.set_title('네이버 쇼핑에 등록된 주요 홍삼 제품 브랜드',fontsize = 20) for x,y in enumerate(list(brand_top_10['Number of Products'])): ax.annotate(f"{y}", xy=(x, y+10), va = 'center', ha='center',fontweight='light', fontfamily='serif',fontsize=15, color='#4a4a4a')2. 종합비타민 브랜드
어느 집에 가도 쉽게 찾을 수 있는 종합비타민에서는 센트룸이 132개로 가장 많이 등록되어 있는 점을 알 수 있다. 전반적으로 센트룸, 얼라이브, GNC, 세노비스 등 해외 제품들이 많이 포진되어 있다.
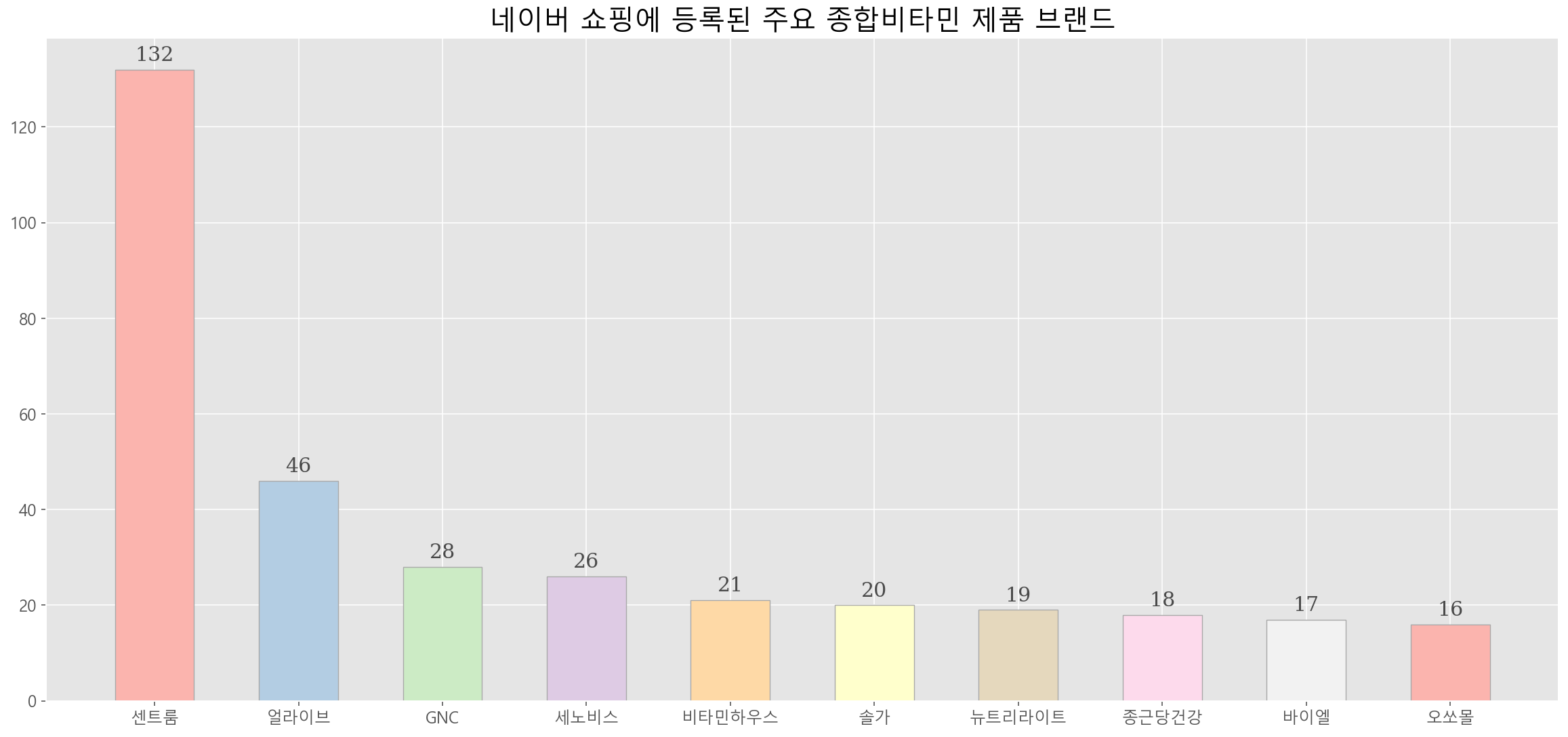
keywords='종합비타민' data2=[] for i in range(1,1001): api = f"https://openapi.naver.com/v1/search/shop.json?query={keywords}&display=100&start={i}" # json 결과 res=requests.get(api,headers=header_parms) if res.json(): for a in res.json()['items']: if a not in data: data2.append(a) else: continue df=pd.DataFrame(data2) df=df.drop_duplicates(['link'],keep='first') df2=df[df['category3']=='비타민제'] brand=pd.DataFrame(df2.groupby(['brand']).count()['title']).reset_index() brand_=brand.sort_values(by='title',ascending=False) brand_=brand_[brand_['brand']!=''] brand_.columns=['Brand','Number of Products'] brand_top_10=brand_.head(10) import seaborn as sns import matplotlib.pyplot as plt from IPython.display import set_matplotlib_formats set_matplotlib_formats("retina") plt.style.use('ggplot') plt.rcParams["font.size"] = 12 plt.rcParams["font.family"] = 'Malgun Gothic' fig, ax = plt.subplots(1,1, figsize=(20, 9)) ax.bar(brand_top_10.Brand, brand_top_10['Number of Products'], width=0.55, edgecolor='darkgray', color=sns.color_palette("Pastel1"), linewidth=0.7) ax.set_title('네이버 쇼핑에 등록된 주요 종합비타민 제품 브랜드',fontsize = 20) for x,y in enumerate(list(brand_top_10['Number of Products'])): ax.annotate(f"{y}", xy=(x, y+3), va = 'center', ha='center',fontweight='light', fontfamily='serif',fontsize=15, color='#4a4a4a')3. 유산균 브랜드
건기식 시장에서 가장 큰 규모라고 볼 수 있는 유산균(프로바이오틱스)에서는 우리가 많이 알고 있는 종근당 락토핏 브랜드가 가장 많이 등록되어 있다. 락토핏이 종근당 브랜드이기 때문에 락토핏과 종근당 제품 수를 합치면 확실히 유산균은 종근당이 점유하고 있다고 해도 무방할 것 같다.
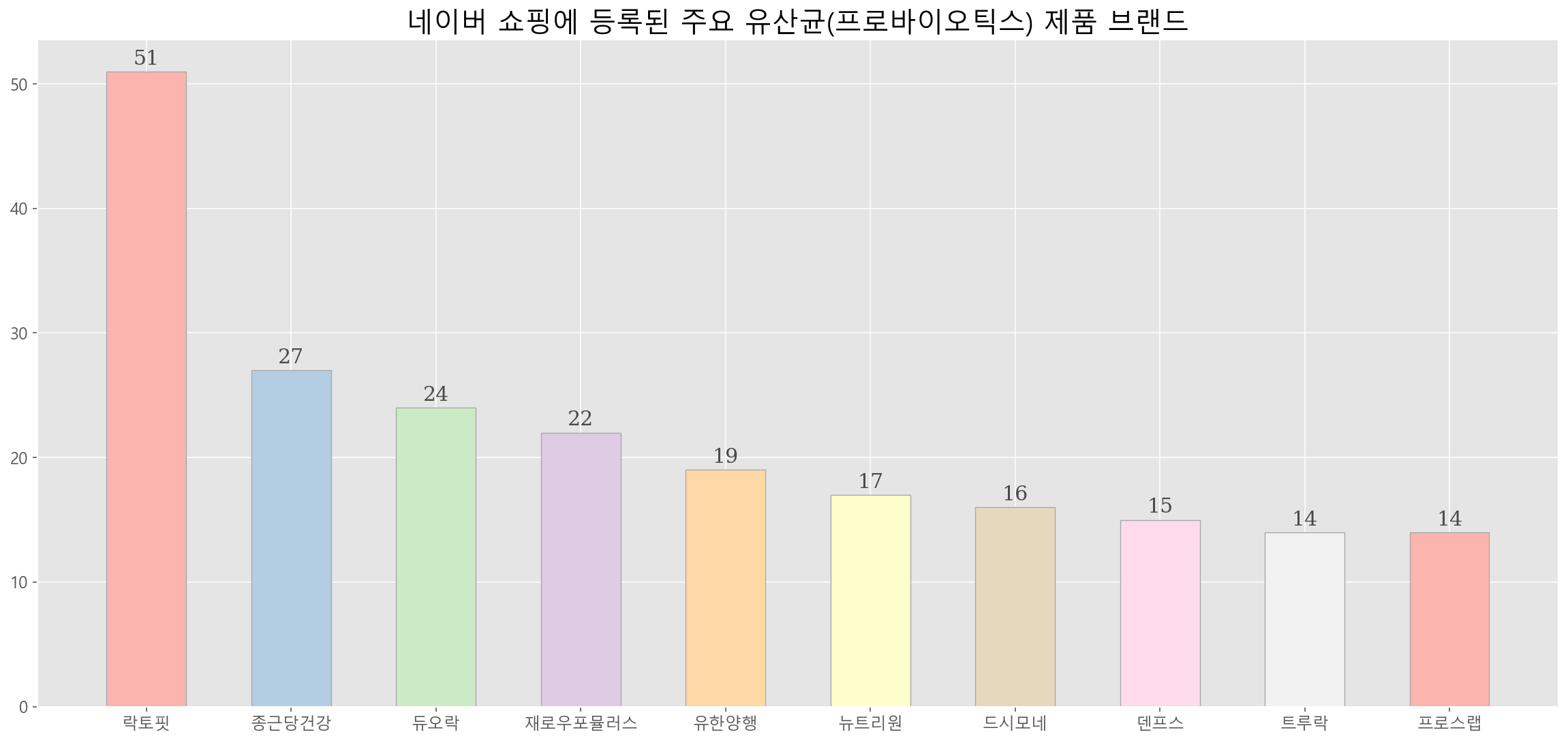
header_parms ={"X-Naver-Client-Id":'Gx_kKVZQ4lhQ5_KXYLnd',"X-Naver-Client-Secret":'FMHquYWP07'} keywords='유산균' data2=[] for i in range(1,1001): api = f"https://openapi.naver.com/v1/search/shop.json?query={keywords}&display=100&start={i}" # json 결과 res=requests.get(api,headers=header_parms) if res.json(): for a in res.json()['items']: if a not in data: data2.append(a) else: continue df=pd.DataFrame(data2) df=df.drop_duplicates(['link'],keep='first') df2=df[df['category4']=='프로바이오틱스'] brand=pd.DataFrame(df2.groupby(['brand']).count()['title']).reset_index() brand_=brand.sort_values(by='title',ascending=False) brand_=brand_[brand_['brand']!=''] brand_.columns=['Brand','Number of Products'] brand_top_10=brand_.head(10) import seaborn as sns import matplotlib.pyplot as plt from IPython.display import set_matplotlib_formats set_matplotlib_formats("retina") plt.style.use('ggplot') plt.rcParams["font.size"] = 12 plt.rcParams["font.family"] = 'Malgun Gothic' fig, ax = plt.subplots(1,1, figsize=(20, 9)) ax.bar(brand_top_10.Brand, brand_top_10['Number of Products'], width=0.55, edgecolor='darkgray', color=sns.color_palette("Pastel1"), linewidth=0.7) ax.set_title('네이버 쇼핑에 등록된 주요 유산균(프로바이오틱스) 제품 브랜드',fontsize = 20) for x,y in enumerate(list(brand_top_10['Number of Products'])): ax.annotate(f"{y}", xy=(x, y+1), va = 'center', ha='center',fontweight='light', fontfamily='serif',fontsize=15, color='#4a4a4a')네이버에 제품이 많이 등록된다고 해서 해당 제품의 시장 점유율이 높다는 건 아니다. 다만 소비자가 네이버에 검색했을 때 어떤 제품이 가장 많이 노출되는지가 실제 구매 결정하는데 큰 영향을 끼치는 만큼 의미가 있었다고 보인다. 건기식 시장에 속한 기업에 투자를 고민하고 있는 분들께는 좋은 참고 자료가 됐으면 한다.
'Data Analysis > Investment' 카테고리의 다른 글
치폴레(Chipotle/CMG) 미국 주가 분석 With FinancialModelingPrep & Python (0) 2021.04.15 MAGA(Microsoft, APPLE, GOOGLE, AMAZON) 기업 주식 비교 분석 With Python (0) 2021.04.10 국내 시중 은행 통계 데이터 분석 #1-1 - 인터넷 전문은행 카카오뱅크 임직원 수 현황 (0) 2021.04.04 국내 시중 은행(신한은행, 국민은행, etc) 통계 분석 #1 - 은행 종사 임직원 수 (0) 2021.04.03 파이썬으로 주식 종목 비교 분석 코카콜라(KO) vs 펩시코(PEP) #2 - 유동비율/현금자산비중/재고자산비중 (0) 2021.04.02